So I have been a bit quieter than normal lately, it’s because I have been working go figure. The new role is a little different than I expected but challenging and rewarding in it’s own way. Now we get to talk about what I have been working on a little, also upfront apologies for length.
The year of VDI is gone we aren’t doing that anymore so stop talking about it. What we do see in the industry is the upward trend in end user solutions moving to virtualized accessed resources. That means not just VDI, but end user applications, mobile device management, user experience management, and the strengthening of DaaS offerings. All of this combines to into what is deemed EUC right?
in the industry is the upward trend in end user solutions moving to virtualized accessed resources. That means not just VDI, but end user applications, mobile device management, user experience management, and the strengthening of DaaS offerings. All of this combines to into what is deemed EUC right?
Of course you are right.
That’s the easy part, defining what it is that I am working to support the tougher part becomes supporting that the market is really moving beyond VDI. For that I looked towards Simon Wardley and Wardley Mapping tools, this is an awesome tool.
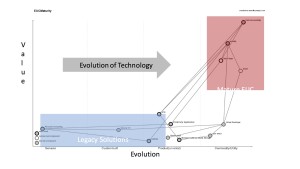
What we look for when we map a technology or industry is first to lay out the value chain, this is a high level representation and is still evolving.
Representatively we see the market starting to shift to more cloud based applications and solutions, well less starting and more continuing. Guess who has a sweet spot for cloud service providers? You guessed it the place where I work ;). In addition we see a push towards DaaS, while technologies are somewhat different we do see some similarities in infrastructure design for shared services, so how does that translate for the enterprise not ready to give up their desktops?
Evolution breeds integration success, isolation is what occurs when something is new or has a degree of unknowns. When VMware and Citrix were first introduced to environments their clusters sat in the corner of the datacenter (ok server closets) like ginger headed classmates not quite accepted by the rest of the servers. Overtime these solutions became mainstream and became core to the design and deployment strategies of pretty much everyone. VDI isn’t by any stretch new, but we isolated from our production workloads because of the resource demand and randomness of workload. Even if vSphere and Xen could handle isolating the production server environment from the desktops we had the issue of the draw on our shared storage environment. How could we have both sit together without impacting the performance of either one?
Hold on a tic, we actually should first start by examining what requirements we expect to see in today’s datacenter when it comes to storage solutions that do not require silo’d management and can support a higher operational cost of ownership through ease of use, scalability and flexibility.
Before I turn this into a marketing post, let’s first think about how we manage this on larger deployable storage solutions. Let’s say an EMC VMAX, not a cost effective VDI solution, but feasible with enough SSDs to handle the workload. In a VMAX config multiple virtual pools would be carved out with policies for each to meet the workload requirements. As cool as the VMAX is it’s not the easiest to scale, nor manage, and the policy sets are not quickly adjusted. You may find yourself adding engines and disk shelves to meet requirements. So while feasible we are lacking some of the requirements we laid out earlier.
VNX similarly has to use RAID pools coupled with virtual storage pools to form the data efficiencies necessary to run VDI. With VNX you have to look at total IOPs and what the FAST VP pool has as assigned FAST cache for the EUC workload. It’s possible to do a mixed workload if you ensure there is another dedicated SSD raid group to pin workloads to but that’s not a guaranteed quality of service feature, as you are sizing and creating unique virtual storage pools to meet requirements and scaling this solution requires more disks or potentially a whole new system.
What about the AFA options?
Great question.
Thanks.
Different AFA solutions handle things in different ways, essentially taking metadata and writing it in either fixed or variable block sizes. There is no doubt that the flash technology is capable of delivering performance for EUC, but what about mixed workloads? Well it comes down to sizing like with most of the traditional storage systems. The market solution is pretty much if you want to throw mixed workloads your AFA can handle it just make sure you have enough capacity and IO. But none of that guarantees that you are going to meet your performance requirements for any given workload. I’ve talked about the need to for corporate governance and SLA’s in enough posts now but they are the crux to IT strategic success. While these other solutions may ease of a piece of this stack here or there they all lack the control of IO demand.
SolidFire on the other hand has taken a unique approach as a company the goal was to 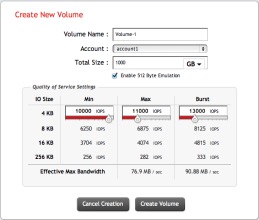 provide cloud service providers with a storage solution that meets the needs of multi-tenant environments to meet performance and reporting requirements that are unique to that market segment. You see the CSPs live and die by SLA’s, that’s how they get paid with uptime and performance being constantly measured. While some solutions have the ability to throttle max IO, SolidFire clusters can also manage the minimum and burst, this means you are ensuring that the minimum IOPs are always being delivered. This means you can run and Oracle DB right next to a EUC workload, right next to a Mongo DB deployment, without any of them impacting the performance of the other.
provide cloud service providers with a storage solution that meets the needs of multi-tenant environments to meet performance and reporting requirements that are unique to that market segment. You see the CSPs live and die by SLA’s, that’s how they get paid with uptime and performance being constantly measured. While some solutions have the ability to throttle max IO, SolidFire clusters can also manage the minimum and burst, this means you are ensuring that the minimum IOPs are always being delivered. This means you can run and Oracle DB right next to a EUC workload, right next to a Mongo DB deployment, without any of them impacting the performance of the other.
Sure so the guaranteed QoS is sweet, but we want to scale, scalability is the big thing. Well sure you do, what do you want to scale capacity or performance? Is it a matter of needing to ingest more blocks and write the metadata faster or is it a matter of storing more data? SolidFire scales these independently with mix and match nodes for more performance or denser SSDs. Any node, any cluster kid that’s how you have flexibility and meet todays build DC’s at scale needs.
So we have answered the scalability and the performance questions but what about ease of use?
Well SolidFire has some pretty awesome capabilities here too, with API functionality out the ying-yang. Essentially if you want to automate it we got you covered. Not to mention the ability to leverage a pretty user friendly (for storage admin perspective) HTML based management console. Plugins are also available for service consoles in OpenStack and VMware environments. Microsoft is being considered.
But wait there is one other super cool feature that is something enterprises are going to want to look at and that’s replication. Think of how most data replication works, you take the dataset do a comparison between the primary and secondary location and validate that the data is the same block by block, bit by bit. But what if you are storing data based off of a metadata hash? Do you rehydrate that data to it’s native format and validate it across the WAN. But what if that was just a matter of validating the hash on both sides instead? Think of the reduction in data transmission and the speed at which replication would occur.
