
Lest we throw fuel onto yet another twitter war, I will say thanks to Chad Sakac for inspiring this post, some of what I am about to expound upon was directly lifted from Chad’s blog on understanding storage architectures, while some of this will show disagreement with the way in which he divided the archetypes up I think the essence of what his goal was will still show through.
A different take:
Chad took an approach of 4 storage types, which he has since refined and updated. His take is depicted like this:
I agree that putting storage types in buckets is important both from an industry perspective as well as from customer understanding and decision making viewpoint. The K.I.S.S. principal needs to apply to all things we do. If you are unfamiliar K.I.S.S. stands for Keep It Simple Stupid! So let’s try and make this as simple as possible.
In my view storage breaks into the following categories (admittedly I would reverse Scale Up and Scale Out because of architecture preconceived connotations but I don’t want to stray too far from what is becoming understood by the industry)
1) Storage Islands
2) Scale Up, Dual controller, add shelves for capacity, stuck on performance
3) Scale Up, Hub & Spoke
4) Scale Out, add performance and or capacity linearly as needed
5) Bring your own Platform (BYOP)

Sorry I don’t have a graphics department to help with art.
Let’s get into what these are, Storage Islands are just that, they are dedicated storage solutions for specific use cases, either DASD or dedicated storage appliances purpose built. These storage types tend to require a SATADOM, a Mezzanine card or some other proprietary connection technology at the host\compute layer. Storage islands are seen all over the place, High Performance Compute, High transactional databases, isolated environments that sit in both unnecessarily and totally necessarily air gapped networks.
Scale Up, Dual controllers are the traditional storage arrays that we all have used and know, these solutions are limited by the controller heads as to the way in which you can grow performance, capacity can be gained up to the disk shelf limits. These architectures are versatile and general purpose. Scale Up dual controllers can work for organizations that consume IT in planned growth segments, top down controls and need various protocols.
Scale Up, hub and spoke this is what Chad called scale out tightly coupled, the thing is, this architecture is much closer to traditional scale up. Controller sets are tied to storage, while mix and match is possible there are limits on rapid scale and on the ability to scale capacity or performance, the economics of scale issue is hit hard here which limits use cases at large scale. The way the storage inter-communicates is typically tied to a unique networking plane to that storage type. In this configuration datasets may stripe across multiple arrays and arrays may form clusters, typically we see caps on either storage scale or performance scale which restrict overall use cases. Scale Up hub and spoke work for environments that have a single or small scope use case and need speed and scale architectures that may require scale at off refresh intervals.
Scale Out, true scale out architectures are when performance or capacity are independent and can grow linearly as needed. There are very few architectures that fall into this category without caveats. The use cases tend to fall into organizations that require easy scaling, limited dependencies, global efficiencies and ability to work with multiple workloads. Scale out architectures are leveraged in multi-modal environments where performance is a concern for some workloads, most solutions have protocol limitations but provide other unique characteristics in order to provide a near share nothing architecture that doesn’t limit scaling performance or capacity independently.
Bring your own platform, this is a very broad bucket, but it needs to be this is where we find things like Ceph and VSAN. I have called this true GLOM storage in the past but it’s the concept of software defined storage controls and taking disparate hardware and layering a storage technology on the top of it. This is an emerging market and has it’s own draw backs. BYOP is one that is wide open, this can be for the cost conscious or the tinkerers out there that are playing with a project but don’t want to mess with storage management in the traditional sense, but it’s hardly set it and forget it and requires proper planning to grow at scale and implement for success, a lot of the time BYOP really should be buy your own hardware that has been certified to run “X” solution.
Part 2 is up next explaining who I believe fits in each bucket.
 in the industry is the upward trend in end user solutions moving to virtualized accessed resources. That means not just VDI, but end user applications, mobile device management, user experience management, and the strengthening of DaaS offerings. All of this combines to into what is deemed EUC right?
in the industry is the upward trend in end user solutions moving to virtualized accessed resources. That means not just VDI, but end user applications, mobile device management, user experience management, and the strengthening of DaaS offerings. All of this combines to into what is deemed EUC right?
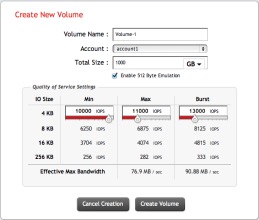 provide cloud service providers with a storage solution that meets the needs of multi-tenant environments to meet performance and reporting requirements that are unique to that market segment. You see the CSPs live and die by SLA’s, that’s how they get paid with uptime and performance being constantly measured. While some solutions have the ability to throttle max IO, SolidFire clusters can also manage the minimum and burst, this means you are ensuring that the minimum IOPs are always being delivered. This means you can run and Oracle DB right next to a EUC workload, right next to a Mongo DB deployment, without any of them impacting the performance of the other.
provide cloud service providers with a storage solution that meets the needs of multi-tenant environments to meet performance and reporting requirements that are unique to that market segment. You see the CSPs live and die by SLA’s, that’s how they get paid with uptime and performance being constantly measured. While some solutions have the ability to throttle max IO, SolidFire clusters can also manage the minimum and burst, this means you are ensuring that the minimum IOPs are always being delivered. This means you can run and Oracle DB right next to a EUC workload, right next to a Mongo DB deployment, without any of them impacting the performance of the other.