
Storage storage storage, ugh it’s like I am unable to escape it in my career. I get it storage is in everything we do but I moved to a cloud company trying to get away. Oh well I guess if I am stuck at least I get to have a portfolio to talk about.
“Cloud storage, is a trap”, “Remember Hotel California by the Eagles, that’s what AWS Storage is”, and the list goes on. I’m not going to get into the FUD part of this save that for the actual customer meetings and let the competition have their hopes and dreams to help them sleep at night.
Before we get too far ahead of ourselves, just like in the world of on-prem storage it’s recommended that all data be encrypted. How do you do this? Well you can use the same encryption and keys that you use in your current data center model, you can use third party encryption, or you can use the Key Management Service (KMS) within AWS itself. Regardless of which you use all keys are owned by you the customer and AWS does not control your data encryption or the keys to decrypt your data under any circumstance.
Now that that’s out of the way what kind of storage do you have in your data center? Most likely you have some block, file, and object, and archive storage right? Well AWS has got you covered.
Simple Storage Service aka S3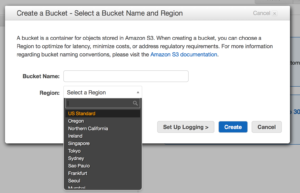
S3 is one of the first services available on AWS. S3 is object based storage, that is replicated across all
availability zones in a region.
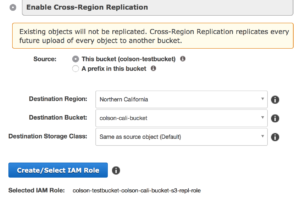 But it can also be tied to cross region replication meaning your data can be replicated closer to the point of utilization or simply for disaster recovery purposes.
But it can also be tied to cross region replication meaning your data can be replicated closer to the point of utilization or simply for disaster recovery purposes.
There are a couple of storage classes for S3 here is a quick chart to explain the difference, each comes with its own cost associated.
| Standard | Standard – IA | Amazon Glacier | |
| Designed for Durability | 99.999999999% | 99.999999999% | 99.999999999% |
| Designed for Availability | 99.99% | 99.9% | N/A |
| Availability SLA | 99.9% | 99% | N/A |
| Minimum Object Size | N/A | 128KB* | N/A |
| Minimum Storage Duration | N/A | 30 days | 90 days |
| Retrieval Fee | N/A | per GB retrieved | per GB retrieved** |
| First Byte Latency | milliseconds | milliseconds | 4 hours |
| Storage Class | object level | object level | object level |
| Lifecycle Transitions | yes | yes | yes |
S3 uses buckets and indexes to organize data off of keys. When you create an S3 bucket you give it a name, only use lower case and know that S3 names are 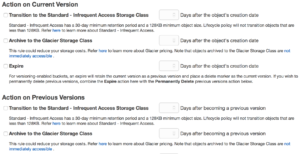 global so make it unique. Permission to buckets are handled via IAM and applied at the bucket level. You can put permissions on objects but if you have more restrictive permissions at the bucket level they will trump whatever you have at the object. S3 has some really great features as well, like logging to track object access, versioning which flags files at change and allows you to roll back to older copies, and lifecycle management. Lifecycle management lets you move objects across classes of S3 storage and even into Glacier which is AWS’ archival storage service, we will get to that in a moment.
global so make it unique. Permission to buckets are handled via IAM and applied at the bucket level. You can put permissions on objects but if you have more restrictive permissions at the bucket level they will trump whatever you have at the object. S3 has some really great features as well, like logging to track object access, versioning which flags files at change and allows you to roll back to older copies, and lifecycle management. Lifecycle management lets you move objects across classes of S3 storage and even into Glacier which is AWS’ archival storage service, we will get to that in a moment.
Elastic Block Storage aka EBS
EBS is the block storage of the AWS world as the name implies. This one should be familiar for anyone coming from the VMware world. EBS can be used as root or secondary volumes for EC2 instances, or as a shared block volume shared across multiple instances (think web content shared across multiple web servers). EBS volumes can be snapshot, and snapshots can be restored from for point in time restoration. EBS can also be added to Raid groups on an EC2 instance, check out the Linux guide or the Windows guide for help on how to configure Raid. You can also encrypt EBS volumes of course, see the guidance for that here.
Elastic File Storage aka EFS
This is the File Systems you are used to but now on the cloud. EFS is one of the newer storage services on AWS. Easy to mount to EC2 instances and replicated across availability zones. EFS automatically scales up and down.
So when do you use EBS vs EFS how about a handy chart?
| Amazon EFS | Amazon EBS PIOPS | ||
| Performance | Per-operation latency | Low, consistent | Lowest, consistent |
| Throughput scale | Multiple GBs per second | Single GB per second | |
| Characteristics | Data Availability/Durability |
Stored redundantly across multiple AZs | Stored redundantly in a single AZ |
| Access | 1 to 1000s of EC2 instances, from multiple AZs, concurrently | Single EC2 instance in a single AZ | |
| Use Cases | Big Data and analytics, media processing workflows, content management, web serving, home directories | Boot volumes, transactional and NoSQL databases, data warehousing & ETL |
Glacier
Glacier is archival storage with 99.999999999% durability, as discussed earlier this is where you lifecycle off S3 data for long term storage. Glacier is by far the cheapest of storage services offered by AWS but it comes with a caveat and that is the time for recovery and availability comes at a cost. There is a 5hr window for data to be available from Glacier. It’s archival storage so treat it as such. There is also a feature called Vault Lock with Glacier that allows you to set policies which turns Glacier storage into WORM capable. No not the awesome dance move from the 80’s Write Once Read Many meaning you can rest assured that the data will not change as such this solves many issues with auditing and can be used for storing logs etc for that purpose.
Storage Gateway
 There is a lot that can be said here about Storage Gateway, this is one of the first on-prem offerings from AWS. Storage Gateway is deployed in your datacenter as either a Hyper-V or VMware VM. You get 3 options for configuration cached volume mode where the most used data has a local copy saving on data transfer rates. Stored volume mode this is where storage gateway is the local volume store and asynchronously backs up data to S3 via point in time snapshots. The last option is Virtual Tape Library (VTL) mode this will allow you to use your backup software to treat the storage gateway as a tape library storing data direct to S3 or to a Virtual Tape Shelf (VTS) backed by Glacier which looks like a standard iSCSI connection.
There is a lot that can be said here about Storage Gateway, this is one of the first on-prem offerings from AWS. Storage Gateway is deployed in your datacenter as either a Hyper-V or VMware VM. You get 3 options for configuration cached volume mode where the most used data has a local copy saving on data transfer rates. Stored volume mode this is where storage gateway is the local volume store and asynchronously backs up data to S3 via point in time snapshots. The last option is Virtual Tape Library (VTL) mode this will allow you to use your backup software to treat the storage gateway as a tape library storing data direct to S3 or to a Virtual Tape Shelf (VTS) backed by Glacier which looks like a standard iSCSI connection.
Snowball
 I would be remised if I didn’t mention what Snowball is, imagine a world in which physics didn’t
I would be remised if I didn’t mention what Snowball is, imagine a world in which physics didn’t
exist. In that world you could push as much data as you wanted across any size pipe day or night, in this world I would also be granted the power of flight cause why not. Wouldn’t that be amazing? Now then back to reality where we live, how do we transfer massive amounts of data from on-premises to S3? The answer comes via FedEx as anyone with Prime already knows. A Snowball is a ruggedized storage appliance that you can order via your AWS console, you specify the bucket that you want the data transferred to, you can move up to 80 TB at a time. There are multiple connection types, and a slick E Ink shipping label that once your data is copied to the appliance flips over and is ready for pick-up from FedEx to be brought to the region of your choice and uploaded.
All of these solutions allow for and strongly encourage data encryption, so be smart and use an encryption key.
 We can do a custom build, but the AWS console has a sweet little VPC wizard we can use. Let’s use the Wizard cause why not. So as you can see you have 4 options. We are going to select Option 2: a VPC with one public and one private subnet.
We can do a custom build, but the AWS console has a sweet little VPC wizard we can use. Let’s use the Wizard cause why not. So as you can see you have 4 options. We are going to select Option 2: a VPC with one public and one private subnet.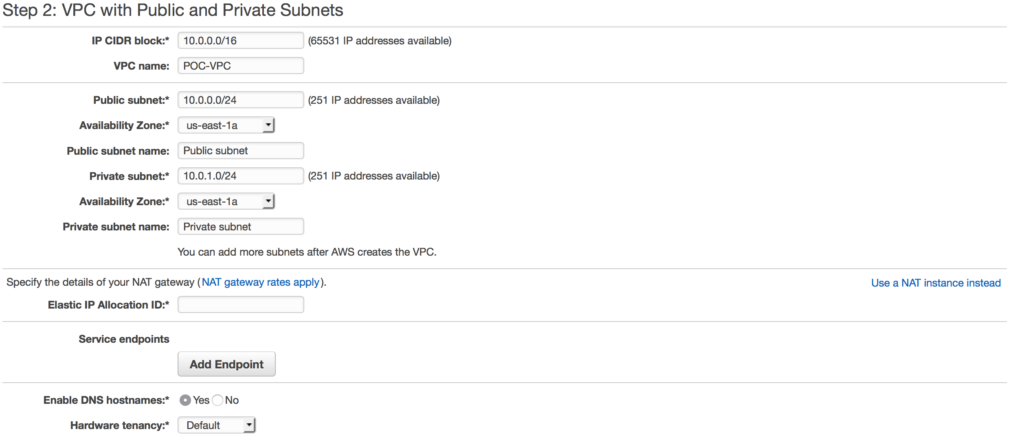 in this case I am choosing a NAT gateway instead of a NAT instance. There are several reasons to choose one over another, one of the main differences is a NAT gateway will auto-scale whereas a NAT instance
in this case I am choosing a NAT gateway instead of a NAT instance. There are several reasons to choose one over another, one of the main differences is a NAT gateway will auto-scale whereas a NAT instance 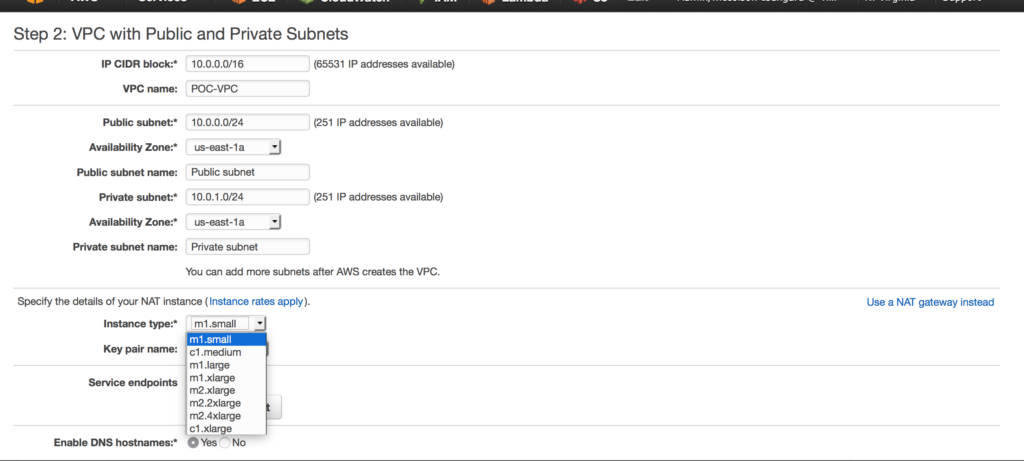 requires a script for failover. Compare your options
requires a script for failover. Compare your options 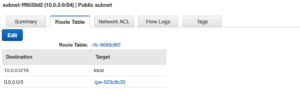 By using the VPC wizard once it’s completed it’s set up our public subnet is also assigned an internet gateway. This means we now have external connectivity to our public subnet.
By using the VPC wizard once it’s completed it’s set up our public subnet is also assigned an internet gateway. This means we now have external connectivity to our public subnet.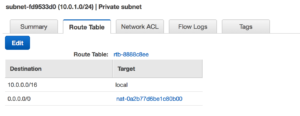 With that same setup the Private subnet is behind the NAT. We are ready to start building out our EC2 instances.
With that same setup the Private subnet is behind the NAT. We are ready to start building out our EC2 instances.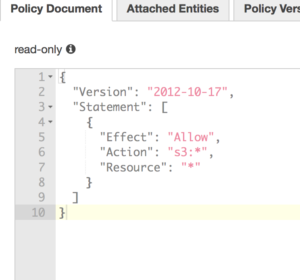
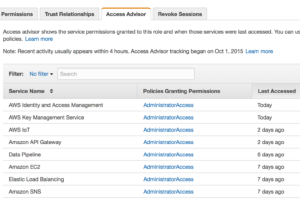 prem administration that is very rarely followed or implemented easily. Here it is just a click of a tab away and an administrator can see what is actually being accessed and make a determination if that role should be limited even further.
prem administration that is very rarely followed or implemented easily. Here it is just a click of a tab away and an administrator can see what is actually being accessed and make a determination if that role should be limited even further.